Academic Materials
This page consolidates all academic material for the Távlink project including reports, source code repositories, a demonstration video, and architectural diagrams.
Reports & Papers
Semester 1 Report
Architecture design paper. Covers the layered OT/IT approach, security at the convergence point, scalability and alignment with IEC 62443 and ISO 27001.
View / DownloadSemester 2 Report
Implementation paper. Push-based telemetry ingestion, MongoDB time-series storage, Dragonfly caching, WebSocket control-room UI and Kubernetes deployment via Forgejo CI/CD.
View / DownloadSource Repositories
All source code is hosted on a self-hosted Forgejo instance. The system is composed of multiple independent components, each in its own repository for separation of concerns and independent CI/CD pipelines.
The prototype branch is the most up-to-date branch in each repository for this academic context. CI/CD is configured and runs against this branch.
Core API & WebSocket
Main backend: REST API and WebSocket server for the control-room real-time interface. Handles configuration, data retrieval and live streaming.
Ingestion Server
Push-based telemetry ingestion API. Validates incoming data against user-defined configurations and stores into MongoDB time-series collections. It also forwards the data for real-time inspection.
Web Interface
Control panel frontend with WebSocket-based control-room view for near real-time monitoring. Connects to Authbridge for identity and Databridge for translations.
Diagrams & Architecture
Visual representations of the system architecture, data flows and component interactions.
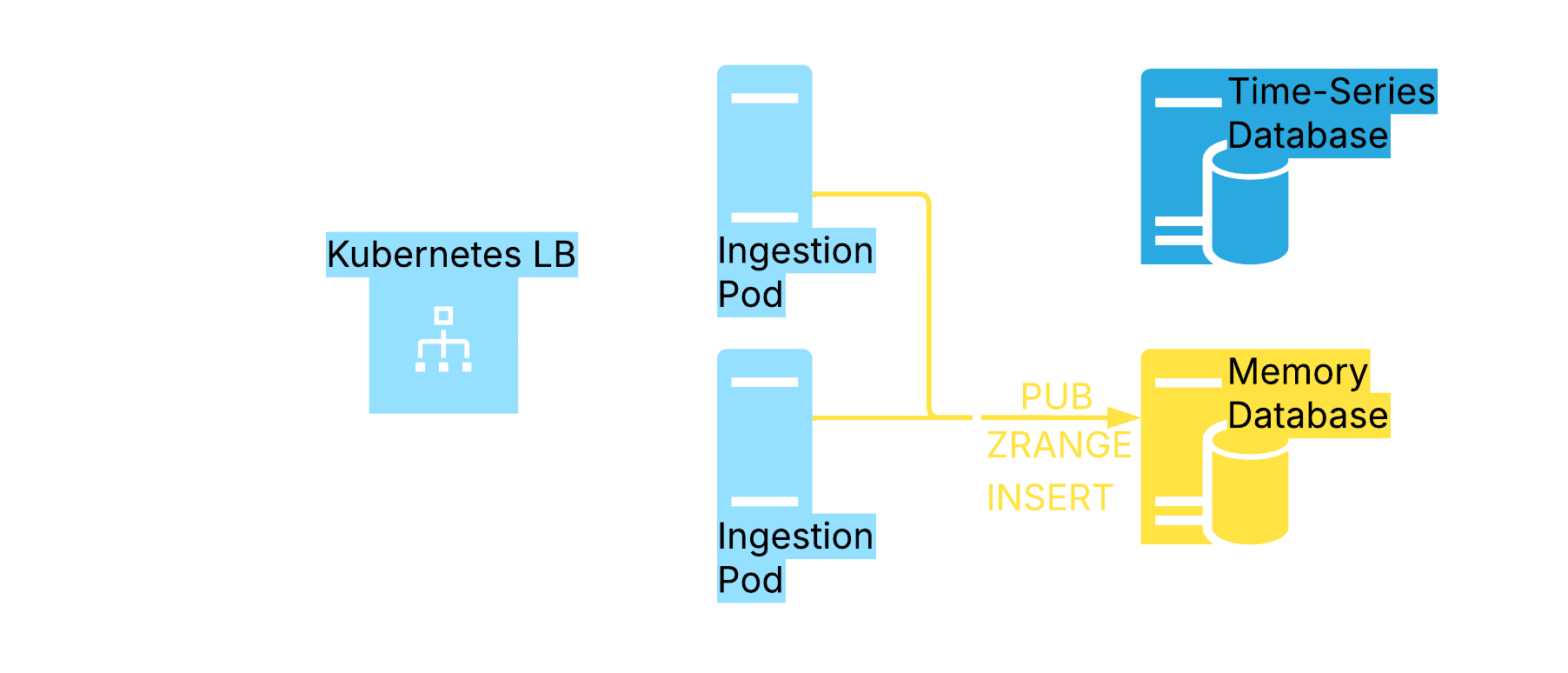
Ingestion Pipeline
How data gets stored in MongoDB time-series collections (top pipeline), and how it flows into memory databases to display it in real time remotely (bottom pipeline).
Core API
How historic telemetry data query and other Core API CRUD capabilities work to display on the interface and allow setting configurations, devices and more.
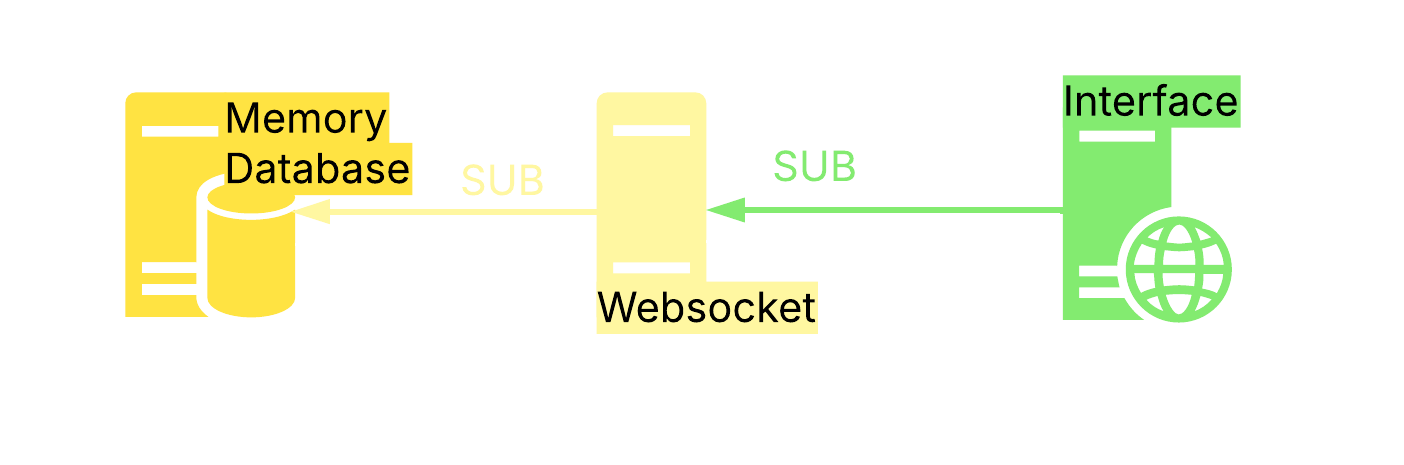
WebSocket Real-Time
How real-time telemetry is shown on the interface and cache burst on initial load.
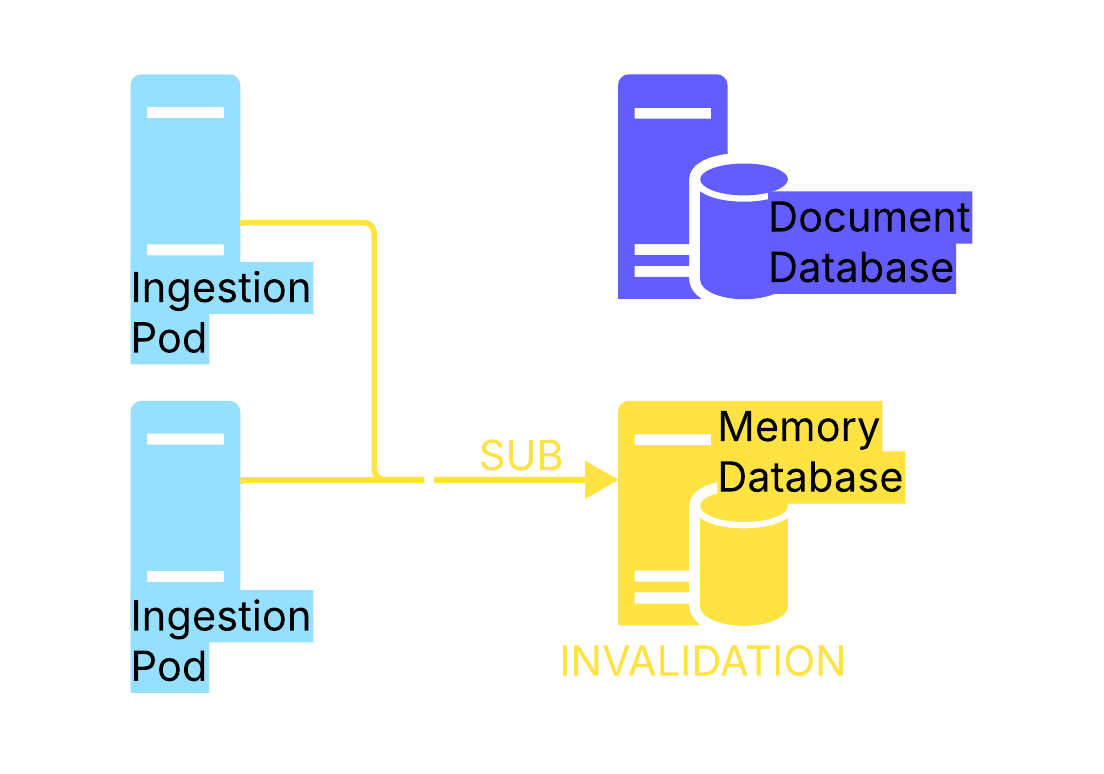
Configuration Distribution
How ingestion servers fetch config. They keep config as local cache and subscribe to Dragonfly to get notified about config invalidation. Upon invalidation the ingestion pods refetch the config for the required devices.
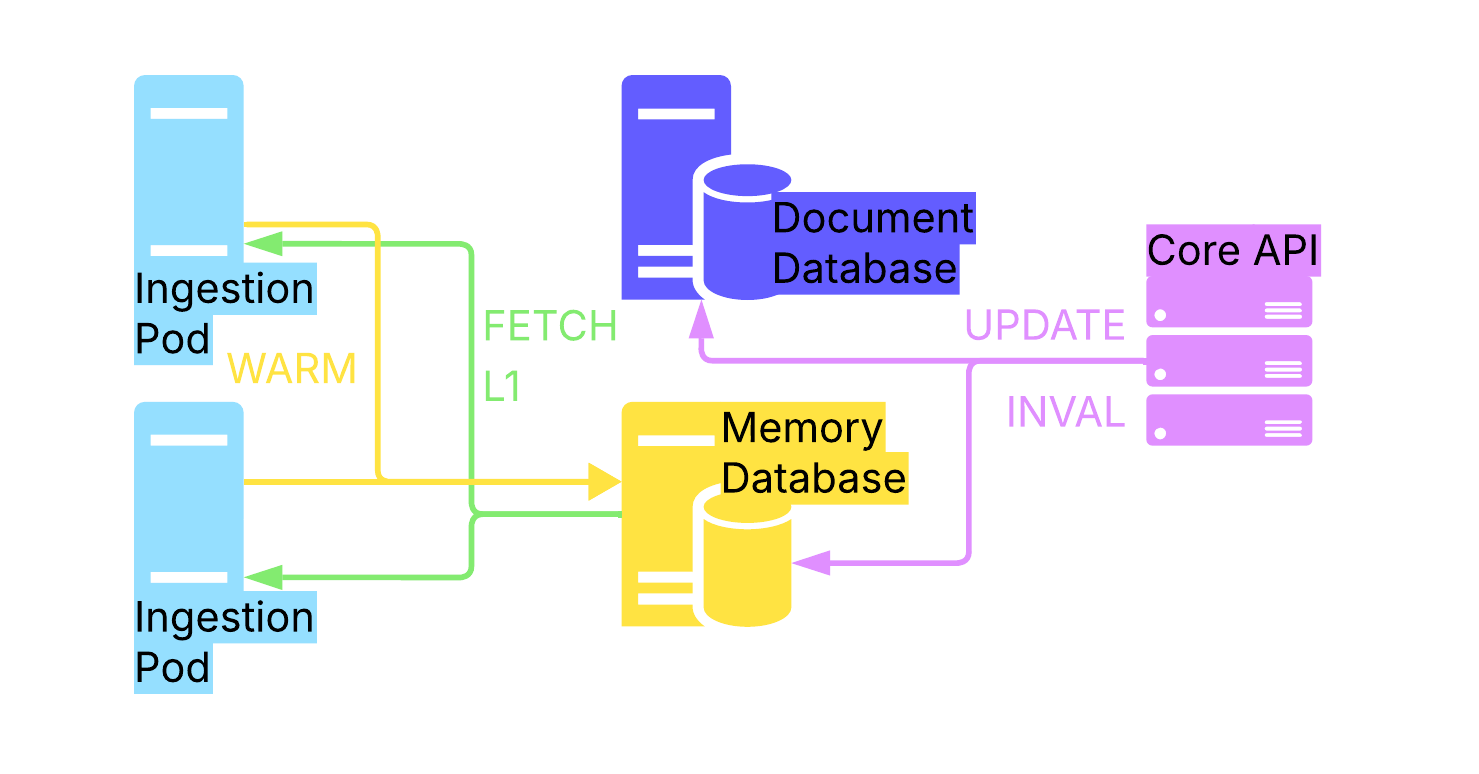
Key Management & Caching
Central source of truth for keys is MongoDB, but in this implementation there is a Dragonfly cache layer to fetch keys faster. When the cache expires the ingestion server calling the memory database rewarms it.
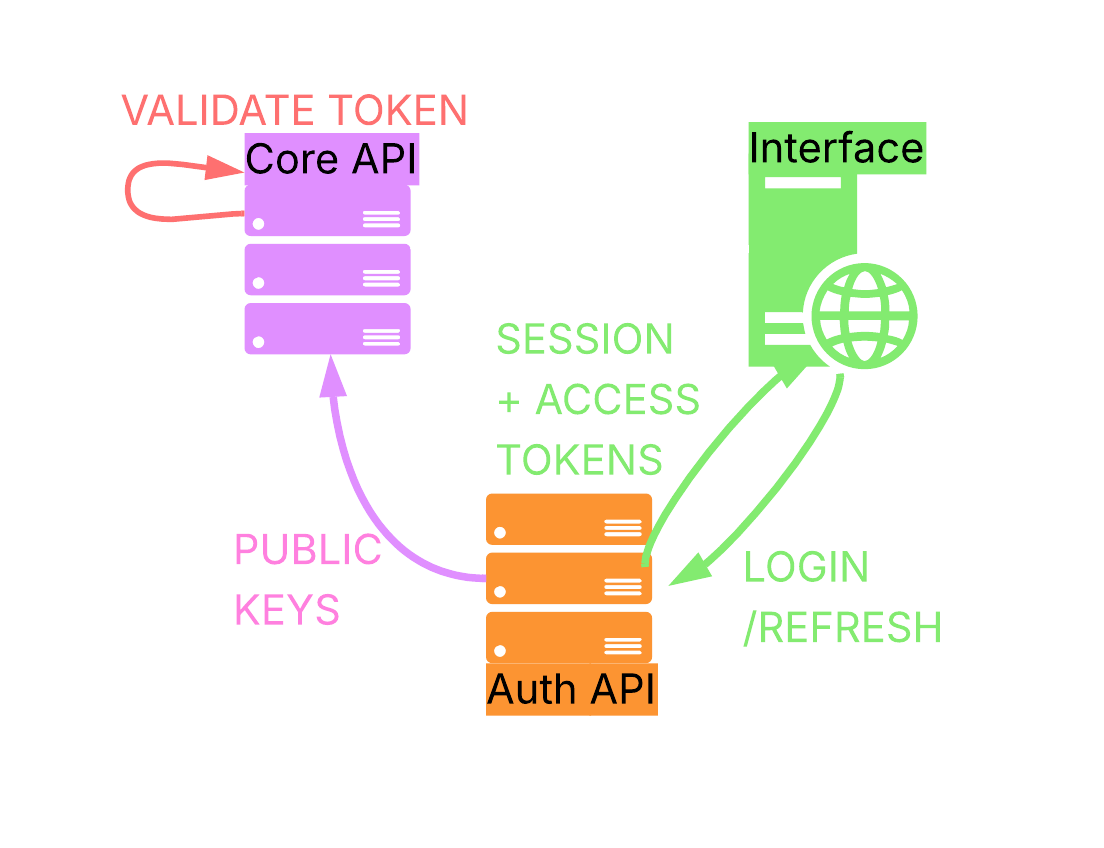
Authentication
Authentication via a proprietary identity and authentication provider (Authbridge / Rifstar ID). Távlink auth and access control is completely stateless thanks to this method.
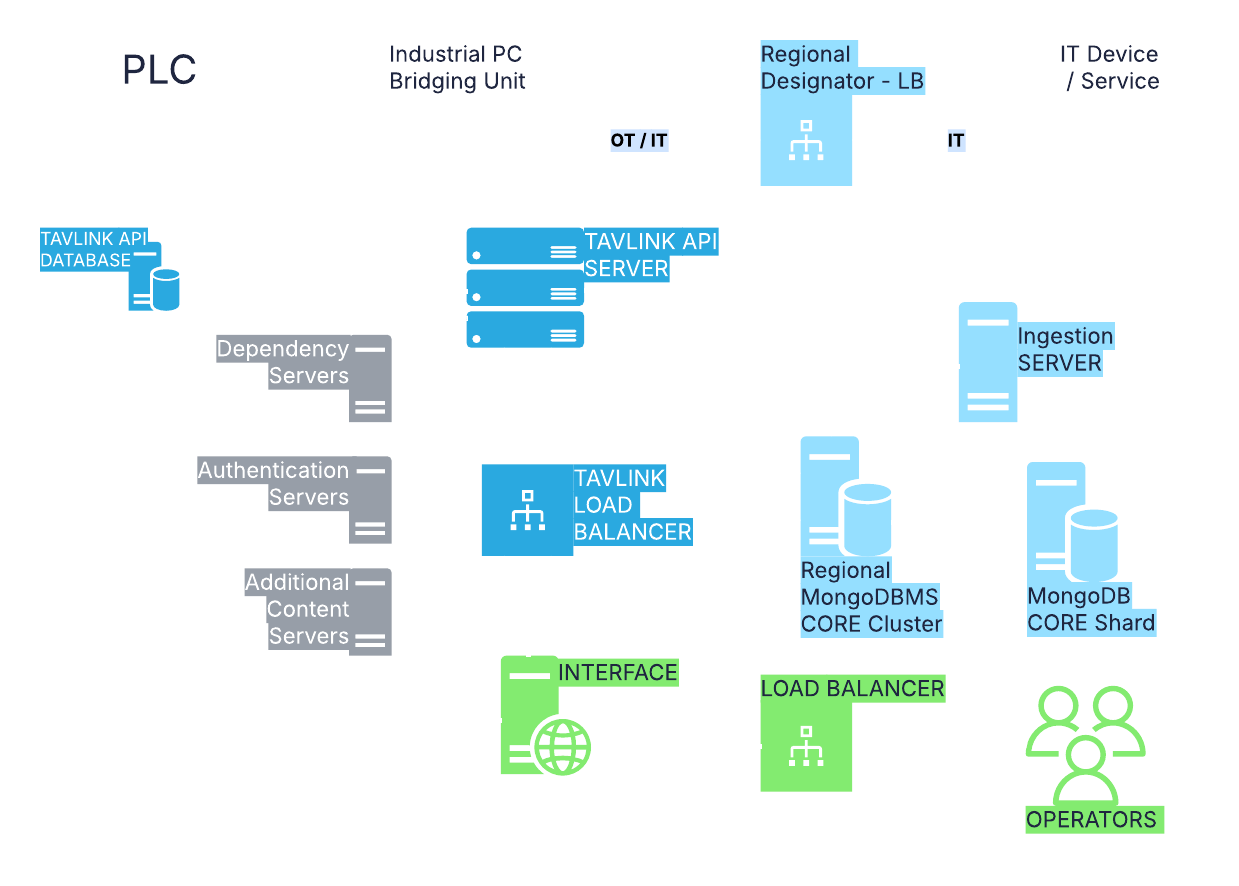
Simplified Overall Architecture
A simplified overview of the general core functions. This does not include cache/memory databases, WebSocket or pub/sub features, but provides a good first look at how the main components interact.
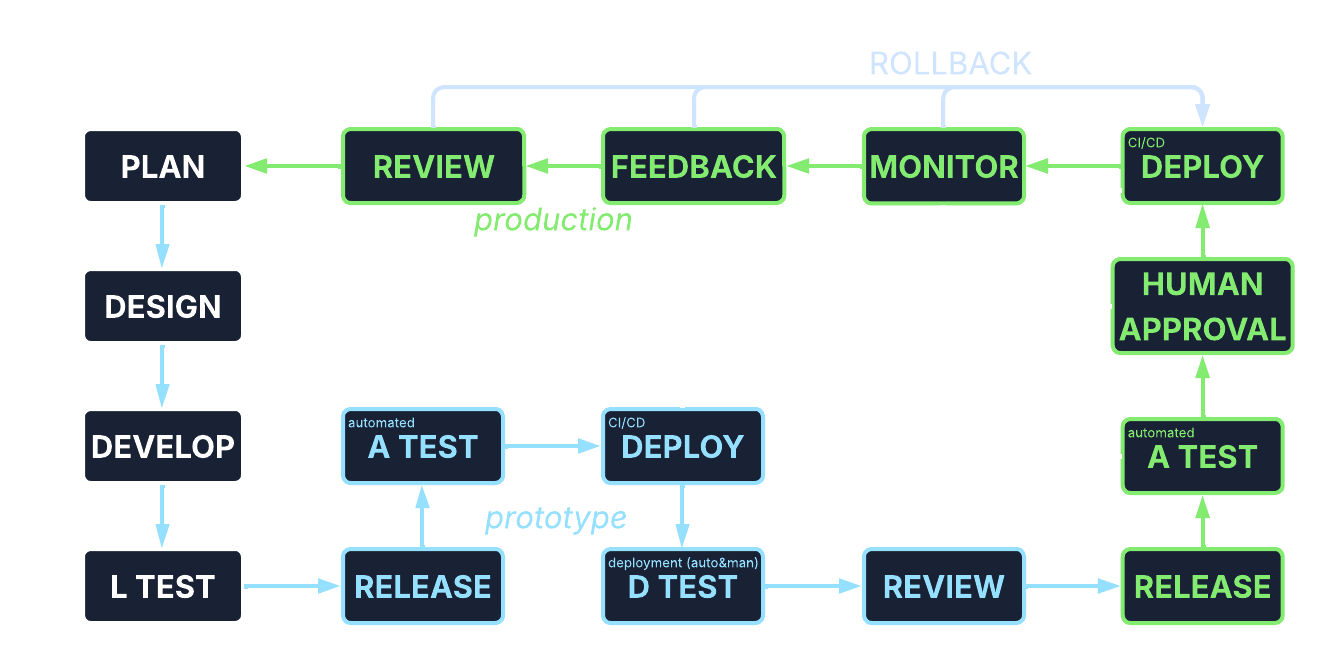
Development Methodology
A simplified version of the target methodology. Only 3 main stages are shown here; in a real-life scenario this would include more (local, playground, prototype, staging, production). In this simplified version the prototype branch serves as pre-production. The procedure itself is correct but of course continuously improving.
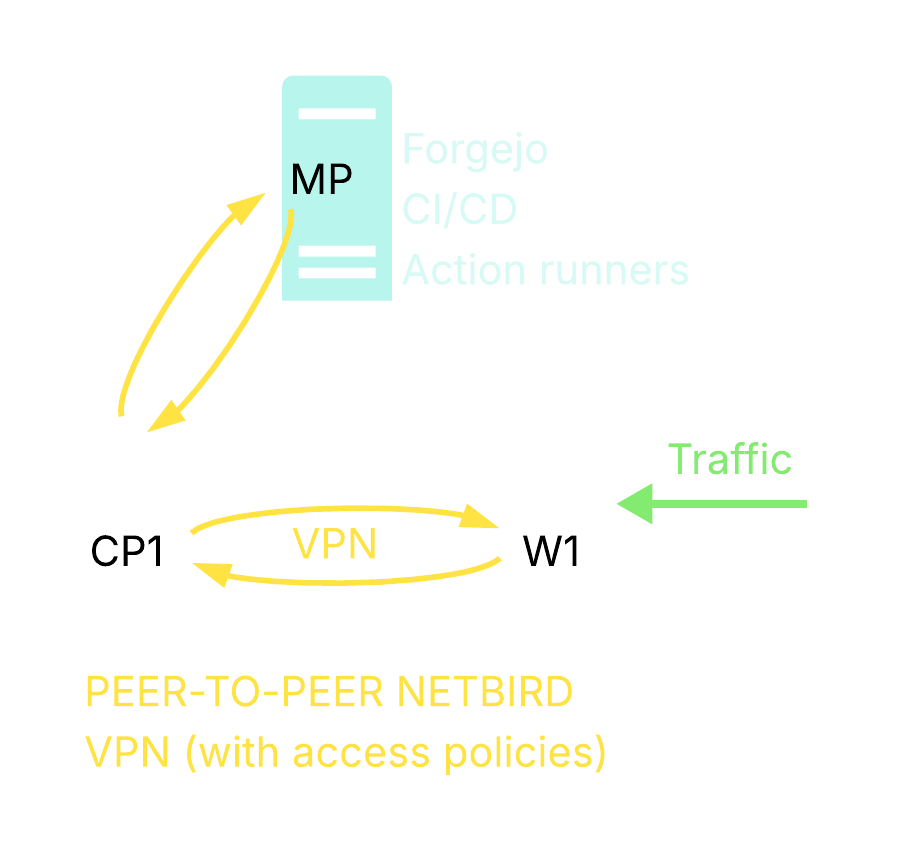
Prototype Deployment
How the simple prototype deployment is done: 3 bare-metal dedicated servers, 2 forming a Kubernetes cluster (1 control plane + 1 node) and a 3rd running Forgejo with CI/CD. The nodes communicate over a self-hosted Netbird peer-to-peer VPN.
Questions?
Any questions regarding the project can be forwarded to the email address shown here.